public int[] twoSum(int[] nums, int target) { int n = nums.length; for (int i = 0; i < n; ++i) { for (int j = i + 1; j < n; ++j) { if (nums[i] + nums[j] == target) { return new int[]{i, j}; } } } return new int[0]; }
时间复杂度:O(N的平方)
空间复杂度:O(1)
哈希表:将数组的值作为key存入map,target - num作为key
1 2 3 4 5 6 7 8 9 10
public int[] twoSum(int[] nums, int target) { Map<Integer, Integer> map = new HashMap<Integer, Integer>(); for (int i = 0; i < nums.length; ++i) { if (map.containsKey(target - nums[i])) { return new int[]{map.get(target - nums[i]), i}; } map.put(nums[i], i); } return new int[0]; }
时间复杂度:O(N)
空间复杂度:O(N)
两数之和(升序)
解法一:二分查找
先固定一个值(从下标0开始),再用二分查找查另外一个值,找不到则固定值向右移动,继续二分查找
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
public int[] twoSearch(int[] numbers, int target) { for (int i = 0; i < numbers.length; ++i) { int low = i, high = numbers.length - 1; while (low <= high) { int mid = (high - low) / 2 + low; if (numbers[mid] == target - numbers[i]) { return new int[]{i, mid}; } else if (numbers[mid] > target - numbers[i]) { high = mid - 1; } else { low = mid + 1; } } } }
public int[] twoPoint(int[] numbers, int target) { int low = 0, high = numbers.length - 1; while (low < high) { int sum = numbers[low] + numbers[high]; if (sum == target) { return new int[]{low + 1, high + 1}; } else if (sum < target) { ++low; } else { --high; } } return new int[]{-1, -1}; }
时间复杂度:O(N)
空间复杂度:O(1)
斐波那契数列
求取斐波那契数列第N位的值。
斐波那契数列:每一位的值等于他前两位数字之和。前两位固定 0,1,1,2,3,5,8。。。。
解法一:暴力递归
1 2 3 4 5 6 7 8 9
public static int calculate(int num) { if (num == 0) { return 0; } if (num == 1) { return 1; } return calculate(num - 1) + calculate(num - 2); }
解法二:去重递归
递归得出具体数值之后、存储到一个集合(下标与数列下标一致),后面递归之前先到该集合查询一次,
如果查到则无需递归、直接取值。查不到再进行递归计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
public static int calculate2(int num) { int[] arr = new int[num + 1]; return recurse(arr, num); }
private static int recurse(int[] arr, int num) { if (num == 0) { return 0; } if (num == 1) { return 1; } if (arr[num] != 0) { return arr[num]; } arr[num] = recurse(arr, num - 1) + recurse(arr, num - 2); return arr[num]; }
解法三:双指针迭代
基于去重递归优化,集合没有必要保存每一个下标值,只需保存前两位即可,向后遍历,得出N的值
排列硬币
总共有 n 枚硬币,将它们摆成一个阶梯形状,第 k 行就必须正好有 k 枚硬币。
给定一个数字 n,找出可形成完整阶梯行的总行数。
n 是一个非负整数,并且在32位有符号整型的范围内
解法一:迭代
从第一行开始排列,排完一列、计算剩余硬币数,排第二列,直至剩余硬币数小于或等于行数
1 2 3 4 5 6 7 8 9
public static int arrangeCoins(int n) { for (int i = 1; i <= n; i++) { n = n - i; if (n <= i) { return i; } } return 0; }
解法二:二分查找
假设能排 n 行,计算 n 行需要多少硬币数,如果大于 n,则排 n/2行,再计算硬币数和 n 的大小关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
public static int arrangeCoins2(int n) { int low = 0, high = n; while (low <= high) { long mid = (high - low) / 2 + low; long cost = ((mid + 1) * mid) / 2; if (cost == n ) { return (int) mid; } else if (cost > n) { high = (int) mid - 1; } else { low = (int) mid + 1; } } return high; }
解法三:牛顿迭代
使用牛顿迭代求平方根,(x + n/x)/2
假设能排 x 行 则 1 + 2 + 3 + …+ x = n,即 x(x+1)/2 = n 推导出 x = 2n - x
1 2 3 4 5 6 7 8
public static double sqrts(double x, int n) { double res = (x + (2 * n - x) / x) / 2; if (res == x) { return x; } else { return sqrts(res, n); } }
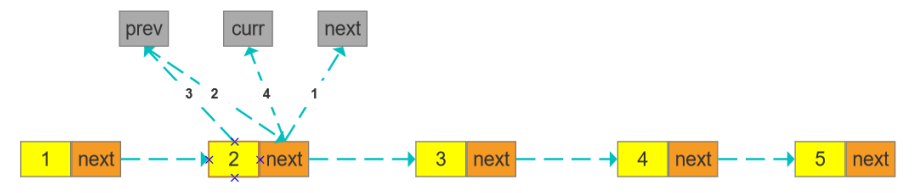
环形链表
给定一个链表,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达该节点,则链表中存在环
如果链表中存在环,则返回 true 。 否则,返回 false 。
解法一:哈希表
1 2 3 4 5 6 7 8 9 10
public static boolean hasCycle(ListNode head) { Set<ListNode> seen = new HashSet<ListNode>(); while (head != null) { if (!seen.add(head)) { return true; } head = head.next; } return false; }
初始化 nums1 和 nums2 的元素数量分别为 m 和 n 。假设 nums1 的空间大小等于 m + n,这样它就
有足够的空间保存来自 nums2 的元素。
解法一:合并后排序
1 2 3 4
public void merge(int[] nums1, int m, int[] nums2, int n) { System.arraycopy(nums2, 0, nums1, m, n); Arrays.sort(nums1); }
时间复杂度 : O((n+m)log(n+m))。
空间复杂度 : O(1)。
解法二:双指针 从前往后
将两个数组按顺序进行比较,放入新的数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
public static int[] merge(int[] nums1, int m, int[] nums2, int n) { int [] nums1_copy = new int[m]; System.arraycopy(nums1, 0, nums1_copy, 0, m);//拷贝数组1 int p1 = 0; // 指向nums1_copy int p2 = 0; // 指向nums2 int p = 0; // 指向nums1
while (p1 < m && p2 < n){ nums1[p++] = nums1_copy[p1] < nums2[p2] ? nums1_copy[p1++] : nums2[p2++]; } if (p1 < m){ System.arraycopy(nums1_copy, p1, nums1, p1 + p2, m + n - p1 - p2); } if (p2 < n){ System.arraycopy(nums2, p2, nums1, p1 + p2, m + n - p1 - p2); } return nums1; }
时间复杂度 : O(n + m)。
空间复杂度 : O(m)。
解法三:双指针优化
从后往前
1 2 3 4 5 6 7
public void merge(int[] nums1, int m, int[] nums2, int n) { int p1 = m - 1; int p2 = n - 1; int p = m + n - 1; while ((p1 >= 0) && (p2 >= 0)) nums1[p--] = (nums1[p1] < nums2[p2]) ? nums2[p2--] : nums1[p1--]; System.arraycopy(nums2, 0, nums1, 0, p2 + 1); }
时间复杂度 : O(n + m)。
空间复杂度 : O(1)。
子数组最大平均数
给一个整数数组,找出平均数最大且长度为 k 的下标连续的子数组,并输出该最大平均数。
滑动窗口:
窗口移动时,窗口内的和等于sum加上新加进来的值,减去出去的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14
public static double findMaxAverage(int[] nums, int k) { int sum = 0; int n = nums.length; // 先统计第一个窗口的和 for (int i = 0; i < k; i++) { sum += nums[i]; } int max = sum; for (int i = k; i < n; i++){ sum = sum - nums[i - k] + nums[i]; max = Math.max(sum, max); } return 1.0 * max / k; }
int min = Integer.MAX_VALUE; if (root.left != null){ min = Math.min(minDepth(root.left), min); } if (root.right != null){ min = Math.min( minDepth(root.right), min); } return min + 1; }
1 2 3 4 5 6 7 8 9 10 11 12 13
public class TreeNode {
public int val; public TreeNode left; public TreeNode right; public int deep;
public static int bfs(int[][] isConnected) { int provinces = isConnected.length; boolean[] visited = new boolean[provinces]; int circles = 0; Queue<Integer> queue = new LinkedList<Integer>(); for (int i = 0; i < provinces; i++) { if (!visited[i]) { queue.offer(i); while (!queue.isEmpty()) { int j = queue.poll(); visited[j] = true; for (int k = 0; k < provinces; k++) { if (isConnected[j][k] == 1 && !visited[k]) { queue.offer(k); } } } circles++; } } return circles; }
static int mergeFind(int[][] isConnected) { int provinces = isConnected.length; int[] head = new int[provinces]; int[] level = new int[provinces]; for (int i = 0; i < provinces; i++) { head[i] = i; level[i] = 1; } for (int i = 0; i < provinces; i++) { for (int j = i + 1; j < provinces; j++) { if (isConnected[i][j] == 1) { merge(i, j, head, level); } } } int count = 0; //找出所有的head for (int i = 0; i < provinces; i++) { if (head[i] == i) { count++; } } return count; }
static int maxScore(int[] nums, int l, int r) { //剩下一个值,只能取该值 if (l == r) { return nums[l]; } int selectLeft = 0, selectRight = nums.length - 1; //剩下大于两个值,先手选一边(使自己得分最高的一边),后手则选使对手得分最低的一边 if ((r - l) >= 2) { int num = maxScore(nums, l + 1, r - 1); selectLeft = nums[l] + Math.min(maxScore(nums, l + 2, r),num); selectRight = nums[r] + Math.min(num, maxScore(nums, l, r - 2)); } //剩下两个值,取较大的 if ((r - l) == 1) { selectLeft = nums[l]; selectRight = nums[r]; } return Math.max(selectLeft, selectRight); }
1 2 3 4 5 6 7 8 9 10
// 差值 static int maxScore1(int[] nums, int l, int r){ //剩下一个值,只能取该值 if (l == r) { return nums[l]; } int selectLeft = nums[l] - maxScore1(nums, l + 1, r); // l + 1 到 r 之间的差值 int selectRight = nums[r] - maxScore1(nums, l , r - 1); return Math.max(selectLeft, selectRight); }
动态规划:使用二维数组存储差值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
public boolean PredictTheWinner(int[] nums) { int length = nums.length; int[][] dp = new int[length][length]; for (int i = 0; i < length; i++) { dp[i][i] = nums[i]; } for (int i = length - 2; i >= 0; i--) { for (int j = i + 1; j < length; j++) { //j = i +1 因此可以优化为一维数组,下标位置相同才有值,据此推导其他的值 // Math.max(nums[i] - dp[j][j], nums[j] - dp[j - 1][j - 1]); dp[i][j] = Math.max(nums[i] - dp[i + 1][j], nums[j] - dp[i][j - 1]); } } return dp[0][length - 1] >= 0; }
public static int bruteForce(String main, String ptn){ if (main == null || ptn == null){ return -1; }
int m = main.length(); int n = ptn.length(); if (n > m){ return bf(ptn, main); }
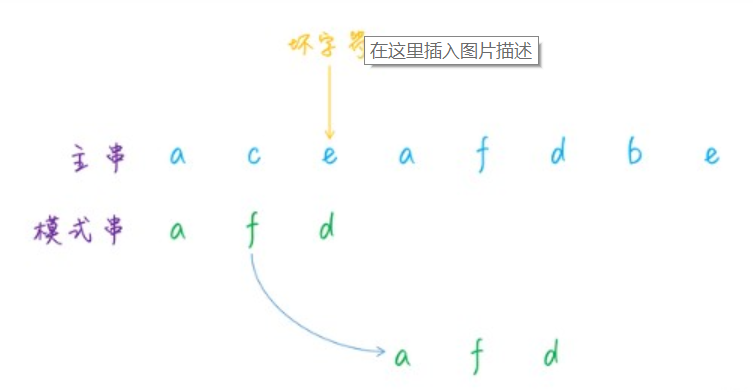
for (int i = 0; i <= m - n; i++) { int j = i; int k = 0; while (k < n && main.charAt(j) == ptn.charAt(k)){ ++j; ++k; } if (k == n){ return i; } } return -1; }
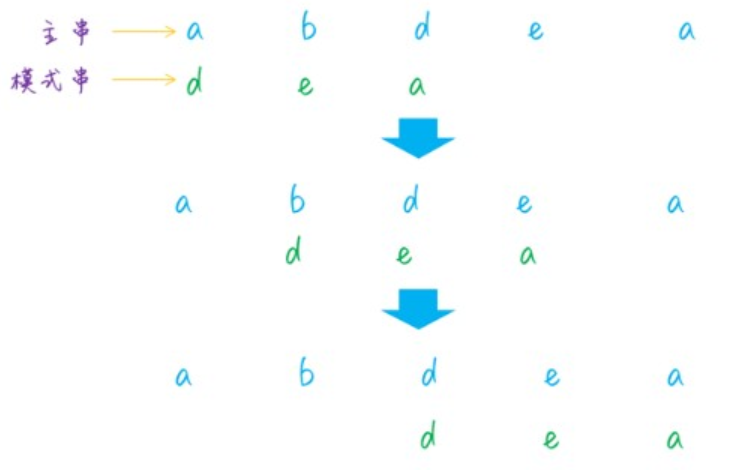
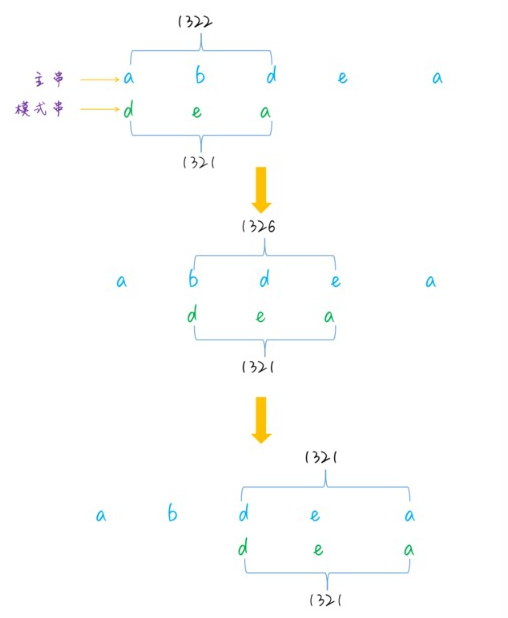
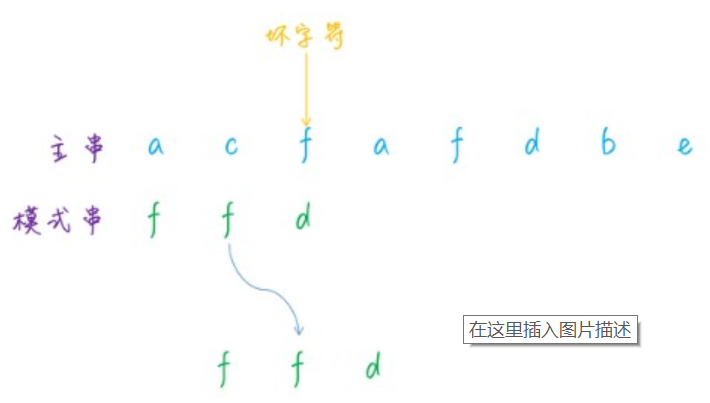
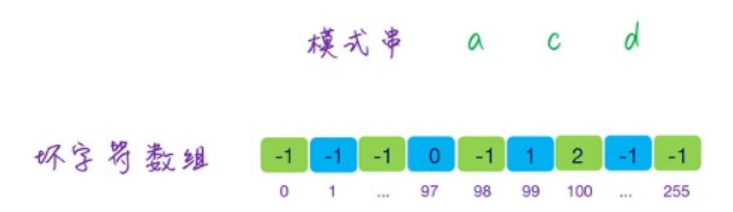
容易想到的一种简单的哈希函数是,直接将每一个字符的 ASCII 码相加,获得一个哈希值。假设主串是 a b d e a,模式串为 d e a ,长度是 3,第一次匹配时,取的子字符串是 a b d,第二次取的子字符串是 b d e,能够看到这两个子字符串是有重合的部分的,只有首尾两个字符不同,因此代码实现能够利用这一点来避免遍历字符串。固然这种哈希函数比较简单,还有其余一些更加精妙的设计,感兴趣的话能够自行研究下。
public static int rabinKarp(String main, String ptn){ if (main == null || ptn == null){ return -1; }
int m = main.length(); int n = ptn.length(); if (n > m){ return rk(ptn, main); }
//计算模式串的hash值 int ptnHash = 0; for (int i = 0; i < n; i++) { ptnHash += ptn.charAt(i); }
int mainHash = 0; for (int i = 0; i <= m - n; i++) { //i == 0时须要遍历计算哈希值,后续不须要 if (i == 0) { for (int j = 0; j < n; j++) { mainHash += main.charAt(j); } }else { mainHash = mainHash - main.charAt(i - 1) + main.charAt(i + n - 1); }
//若是哈希值相同,为避免哈希冲突,再依次遍历比较 if (mainHash == ptnHash){ int k = i; int j = 0; while (j < n && main.charAt(k) == ptn.charAt(j)){ ++k; ++j; } if (j == n){ return i; } } }
return -1; }
模式串和主串之间的匹配是常数时间的,最多只须要遍历 m - n + 1 次,再加上可能存在哈希冲突的状况,所以 RK 算法的整体的时间复杂度大概为 O(m)。
int n = str.length(); for (int i = 0; i < n - 1; i++){ int j = i; int k = 0;
while (j >= 0 && str.charAt(j) == str.charAt(n - k - 1)){ --j; ++k; suffix[k] = j + 1; } if (j == -1){ prefix[k] = true; } } }
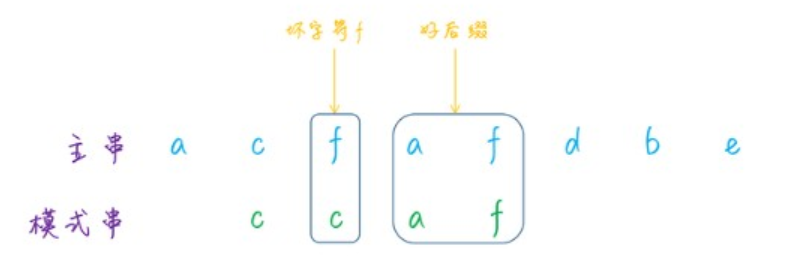
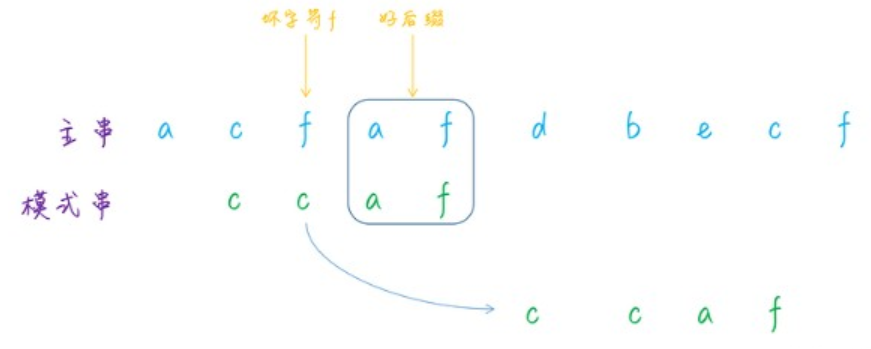
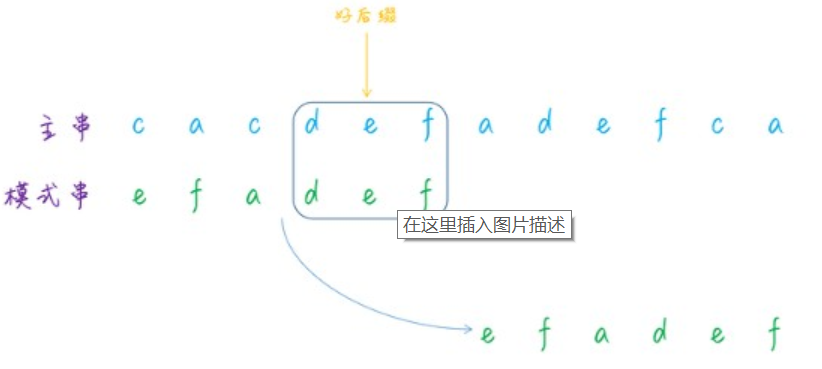
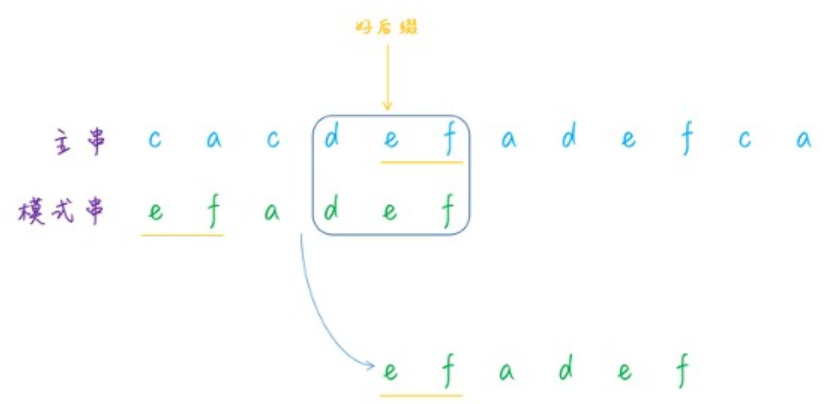
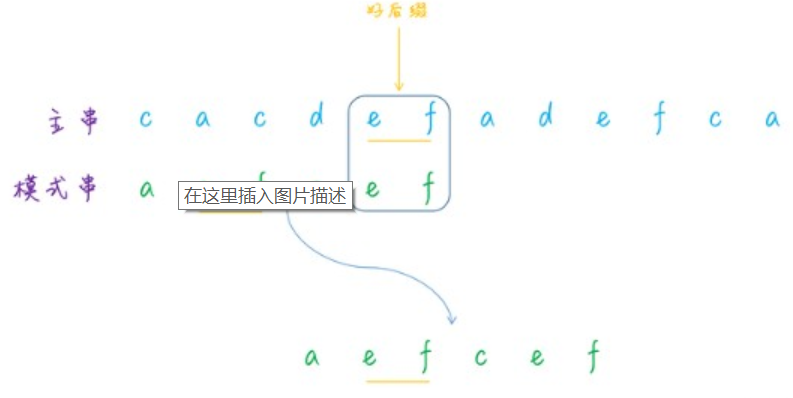
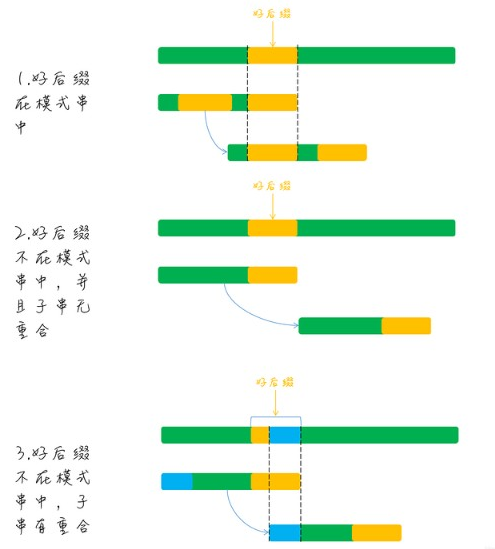
/** * 计算好后缀状况下的移动位数 */ private static int moveWithGS(int n, int j, int[] suffix, boolean[] prefix){ int k = n - j - 1; if (suffix[k] != -1){ return j - suffix[k] + 1; }
for (int i = k - 1; i >= 0; i--) { if (prefix[i]){ return n - i; } }
static int maxMoney(int[] nums, int start, int end){ int first = nums[start], second = Math.max(nums[start], nums[start + 1]); for(int i = start + 2; i <= end; i++){ int temp = second; second = Math.max(first + nums[i], second); first = temp; } return second; }