解释: MyQueue myQueue = new MyQueue(); myQueue.push(1); // queue is: [1] myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue) myQueue.peek(); // return 1 myQueue.pop(); // return 1, queue is [2] myQueue.empty(); // return false
public class DecodeString { public static void main(String[] args) { String s = "3[a2[c]]"; System.out.println(decodeString( s)); } static int ptr = 0; public static String decodeString(String s) { LinkedList<String> stk = new LinkedList<String>(); ptr = 0;
while (ptr < s.length()) { char cur = s.charAt(ptr); if (Character.isDigit(cur)) { // 获取一个数字并进栈 String digits = getDigits(s); stk.addLast(digits); } else if (Character.isLetter(cur) || cur == '[') { // 获取一个字母并进栈 stk.addLast(String.valueOf(s.charAt(ptr++))); } else { ++ptr; LinkedList<String> sub = new LinkedList<String>(); while (!"[".equals(stk.peekLast())) { sub.addLast(stk.removeLast()); } Collections.reverse(sub); // 左括号出栈 stk.removeLast(); // 此时栈顶为当前 sub 对应的字符串应该出现的次数 int repTime = Integer.parseInt(stk.removeLast()); StringBuffer t = new StringBuffer(); String o = getString(sub); // 构造字符串 while (repTime-- > 0) { t.append(o); } // 将构造好的字符串入栈 stk.addLast(t.toString()); } }
return getString(stk); }
public static String getDigits(String s) { StringBuffer ret = new StringBuffer(); while (Character.isDigit(s.charAt(ptr))) { ret.append(s.charAt(ptr++)); } return ret.toString(); }
public static String getString(LinkedList<String> v) { StringBuffer ret = new StringBuffer(); for (String s : v) { ret.append(s); } return ret.toString(); } }
public class DailyTemperatures { public static void main(String[] args) { int[] nums = {73,74,75,71,69,72,76,73}; System.out.println(Arrays.toString(new DailyTemperatures().dailyTemperatures(nums))); }
/*用倒序遍历数组来求解*/ public int[] dailyTemperatures(int[] temperatures) { int length = temperatures.length; int[] ret = new int[length];
/*从右向左遍历,数组最后一个元素无需处理*/ for (int i = length - 2; i >= 0; i--) { /*backIdx表示从当前元素开始往后寻找获得需要的结果, backIdx=backIdx+ret[backIdx]是为了利用已经有的结果进行跳跃*/ for (int backIdx = i + 1; backIdx < length; backIdx=backIdx+ret[backIdx]) { if (temperatures[backIdx] > temperatures[i]) { ret[i] = backIdx - i; break; } else if (ret[backIdx] == 0) {/*遇到0表示后面不会有更大的值,那当然当前值就应该也为0*/ ret[i] = 0; break; } } } return ret; }
// 栈 public int[] dailyTemperatures1(int[] temperatures) { int[] ret = new int[temperatures.length]; Stack<Integer> stack = new Stack<>(); for(int i = 0; i < temperatures.length; i++){ while (!stack.isEmpty() && temperatures[stack.peek()] < temperatures[i]){ int index = stack.pop(); ret[index] = i - index; } stack.push(i); } return ret; } }
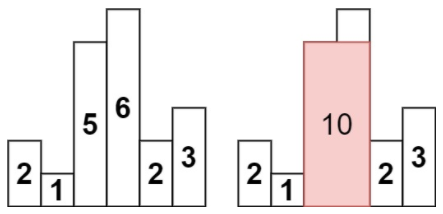
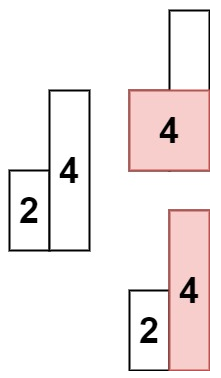
/*基于单调栈的实现*/ public int largestRectangleArea(int[] heights) { int len = heights.length; if (len == 0) { return 0; } if (len == 1) { return heights[0]; }
int result = 0; Deque<Integer> stack = new LinkedList<Integer>(); /*遍历数组*/ for (int i = 0; i < len; i++) { while (!stack.isEmpty() && heights[i] < heights[stack.peekLast()]) { /*当前需要计算面积的元素的下标*/ int curIndex = stack.pollLast(); /*获得当前元素的值,也就是矩形的高*/ int curHeight = heights[curIndex]; /*计算矩形的宽*/ int curWidth; if (stack.isEmpty()) { /*栈为空,表示目前遍历过所有元素都比当前的i要大,i是最小的一个, 宽度就可以直接取i的值*/ curWidth = i; } else { curWidth = i - stack.peekLast() - 1; } result = Math.max(result, curHeight * curWidth); } stack.addLast(i); }
/*处理目前还在栈中的元素*/ while (!stack.isEmpty()) { int curHeight = heights[stack.pollLast()]; int curWidth; if (stack.isEmpty()) { curWidth = len; } else { curWidth = len - stack.peekLast() - 1; } result = Math.max(result, curHeight * curWidth); } return result; } }
public int calculate(String s) { Deque<Integer> ops = new LinkedList<Integer>(); ops.push(1); int sign = 1;
int ret = 0; int n = s.length(); int i = 0; while (i < n) { if (s.charAt(i) == ' ') { i++; } else if (s.charAt(i) == '+') { sign = ops.peek(); i++; } else if (s.charAt(i) == '-') { sign = -ops.peek(); i++; } else if (s.charAt(i) == '(') { ops.push(sign); i++; } else if (s.charAt(i) == ')') { ops.pop(); i++; } else { long num = 0; while (i < n && Character.isDigit(s.charAt(i))) { num = num * 10 + s.charAt(i) - '0'; i++; } ret += sign * num; } } return ret; } }
保持:如果 i=k 时性质成立,即第 k 轮中出队 sk 的元素是第 k 层的所有元素,并且顺序从左到右。因为对树进行广度优先搜索的时候由低 k 层的点拓展出的点一定也只能是 k+1 层的点,并且 k+1 层的点只能由第 k 层的点拓展到,所以由这 sk 个点能拓展到下一层所有的 sk+1个点。又因为队列的先进先出(FIFO)特性,既然第 k 层的点的出队顺序是从左向右,那么第 k+1 层也一定是从左向右。至此,我们已经可以通过数学归纳法证明循环不变式的正确性。
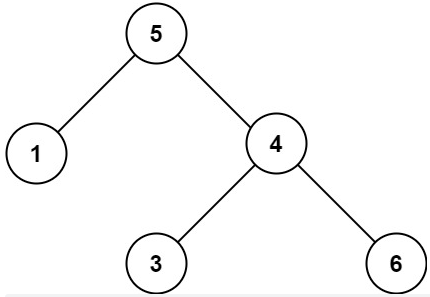
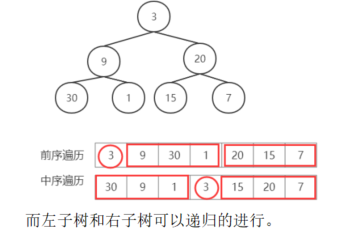
我们遍历 10,这时情况就不一样了。我们发现 index 恰好指向当前的栈顶节点 4,也就是说 4 没有左儿子,那么 10 必须为栈中某个节点的右儿子。那么如何找到这个节点呢?栈中的节点的顺序和它们在前序遍历中出现的顺序是一致的,而且每一个节点的右儿子都还没有被遍历过,那么这些节点的顺序和它们在中序遍历中出现的顺序一定是相反的。
因此我们可以把 index 不断向右移动,并与栈顶节点进行比较。如果 index 对应的元素恰好等于栈顶节点,那么说明我们在中序遍历中找到了栈顶节点,所以将 index 增加 1 并弹出栈顶节点,直到 index 对应的元素不等于栈顶节点。按照这样的过程,我们弹出的最后一个节点 x 就是 10 的双亲节点,这是因为 10 出现在了 x 与 x 在栈中的下一个节点的中序遍历之间,因此 10 就是 x 的右儿子。
public TreeNode myBuildTree(int[] preorder, int[] inorder, int preorder_left, int preorder_right, int inorder_left, int inorder_right) { if (preorder_left > preorder_right) { return null; }
public TreeNode buildTree(int[] preorder, int[] inorder) { int n = preorder.length; // 构造哈希映射,帮助我们快速定位根节点 indexMap = new HashMap<Integer, Integer>(); for (int i = 0; i < n; i++) { indexMap.put(inorder[i], i); } return myBuildTree(preorder, inorder, 0, n - 1, 0, n - 1); }
// 迭代 public TreeNode buildTree(int[] preorder, int[] inorder) { if (preorder == null || preorder.length == 0) { return null; } TreeNode root = new TreeNode(preorder[0]); Deque<TreeNode> stack = new LinkedList<TreeNode>(); stack.push(root); int inorderIndex = 0; for (int i = 1; i < preorder.length; i++) { int preorderVal = preorder[i]; TreeNode node = stack.peek(); if (node.val != inorder[inorderIndex]) { node.left = new TreeNode(preorderVal); stack.push(node.left); } else { while (!stack.isEmpty() && stack.peek().val == inorder[inorderIndex]) { node = stack.pop(); inorderIndex++; } node.right = new TreeNode(preorderVal); stack.push(node.right); } } return root; }
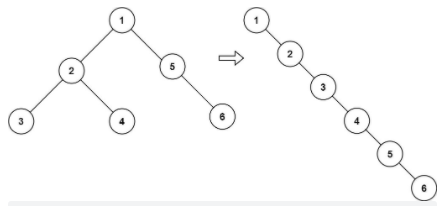
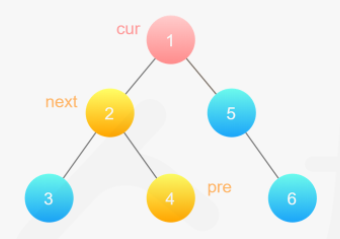
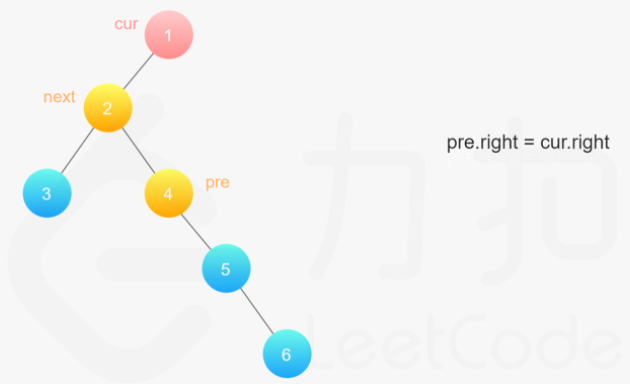
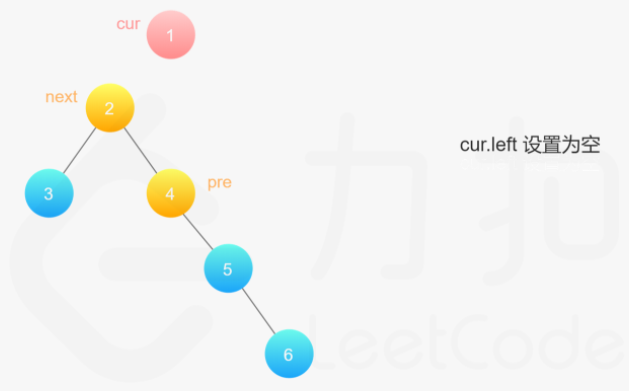
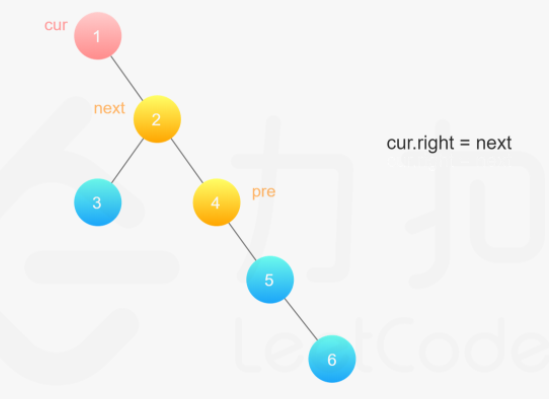
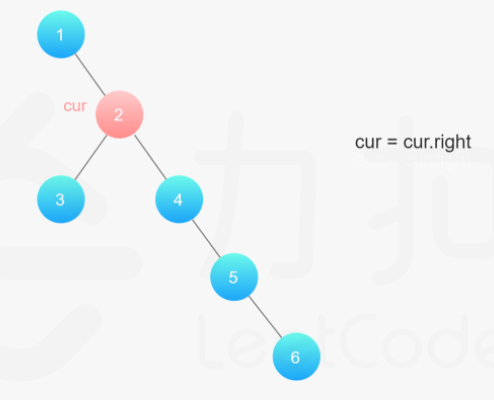
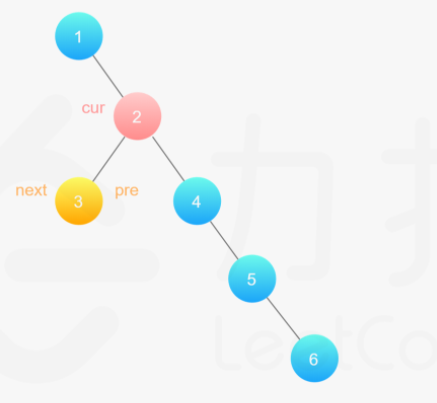
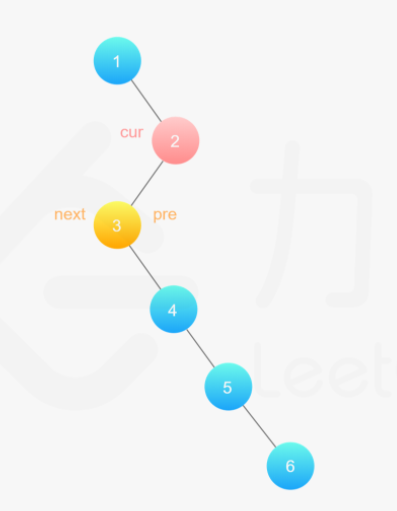
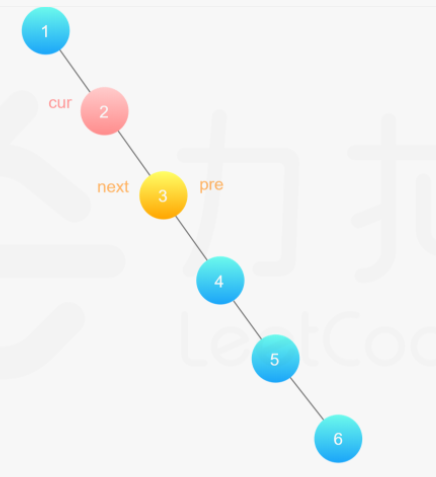
**(LeetCode-114) **二叉树展开为链表
题目
给你二叉树的根结点 root ,请你将它展开为一个单链表:
展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null
public class Flatten { public static void main(String[] args) { TreeNode node6 = new TreeNode(6); TreeNode node4 = new TreeNode(4); TreeNode node3 = new TreeNode(3); TreeNode node5 = new TreeNode(5, null,node6); TreeNode node2 = new TreeNode(2, node3,node4); TreeNode node1 = new TreeNode(1, node2, node5); new Flatten().flatten( node1); System.out.println(""); }
public class RightSideView { public static void main(String[] args) { TreeNode node6 = new TreeNode(6); TreeNode node4 = new TreeNode(4); TreeNode node3 = new TreeNode(3); TreeNode node5 = new TreeNode(5, null,null); TreeNode node2 = new TreeNode(2, node3,node4); TreeNode node1 = new TreeNode(1, node2, node5); new RightSideView().rightSideView( node1); System.out.println(""); }