ElasticSearch计分原理及数据建模
文档分值_score计算底层原理
boolean model
1
2
3
| query "hello world" --> hello / world / hello & world
bool --> must/must not/should --> 过滤 --> 包含 / 不包含 / 可能包含
doc --> 不打分数 --> 正或反 true or false --> 为了减少后续要计算的doc的数量,提升性能
|
relevance score算法
relevance score算法, 简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度
Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法
Term frequency:搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关
1
2
3
| 搜索请求:hello world
doc1:hello you, and world is very good
doc2:hello, how are you
|
Inverse document frequency:搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关
1
2
3
| 搜索请求:hello world
doc1:hello, tuling is very good
doc2:hi world, how are you
|
比如说,在index中有1万条document,hello这个单词在所有的document中,一共出现了1000次;world这个单词在所有的document中,一共出现了100次
Field-length norm:field长度,field越长,相关度越弱
搜索请求:hello world
1
2
| doc1:{ "title": "hello article", "content": "...... N个单词" }
doc2:{ "title": "my article", "content": "...... N个单词,hi world" }
|
hello world在整个index中出现的次数是一样多的
doc1更相关,title field更短
vector space model(空间向量模型)
- query vector:查询向量
- doc vector:文档向量
多个term对一个doc的总分数
query vector
hello world –> es会根据hello world在所有doc中的评分情况,计算出一个query vector,query向量
hello这个term,给的基于所有doc的一个评分就是3
world这个term,给的基于所有doc的一个评分就是6
[3, 6]
doc vector
3个doc,一个包含hello,一个包含world,一个包含hello 以及 world
3个doc
doc1:包含hello –> [3, 0]
doc2:包含world –> [0, 6]
doc3:包含hello, world –> [3, 6]
会给每一个doc,拿每个term计算出一个分数来,hello有一个分数,world有一个分数,再拿所有term的分数组成一个doc vector
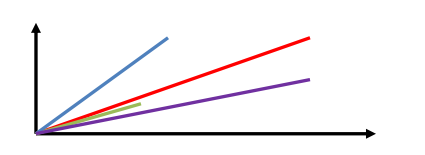
画在一个图中,取每个doc vector对query vector的弧度,给出每个doc对多个term的总分数
每个doc vector计算出对query vector的弧度,最后基于这个弧度给出一个doc相对于query中多个term的总分数
弧度越大,分数月底; 弧度越小,分数越高
如果是多个term,那么就是线性代数来计算,无法用图表示
数据建模
1、案例:设计一个用户document数据类型,其中包含一个地址数据的数组,这种设计方式相对复杂,但是在管理数据时,更加的灵活。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| PUT /user_index
{
"mappings": {
"properties": {
"login_name" : {
"type" : "keyword"
},
"age " : {
"type" : "short"
},
"address" : {
"properties": {
"province" : {
"type" : "keyword"
},
"city" : {
"type" : "keyword"
},
"street" : {
"type" : "keyword"
}
}
}
}
}
}
|
但是上述的数据建模有其明显的缺陷,就是针对地址数据做数据搜索的时候,经常会搜索出不必要的数据,如:在下述数据环境中,搜索一个province为北京,city为天津的用户。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| PUT /user_index/_doc/1
{
"login_name" : "jack",
"age" : 25,
"address" : [
{
"province" : "北京",
"city" : "北京",
"street" : "枫林三路"
},
{
"province" : "天津",
"city" : "天津",
"street" : "华夏路"
}
]
}
PUT /user_index/_doc/2
{
"login_name" : "rose",
"age" : 21,
"address" : [
{
"province" : "河北",
"city" : "廊坊",
"street" : "燕郊经济开发区"
},
{
"province" : "天津",
"city" : "天津",
"street" : "华夏路"
}
]
}
|
执行的搜索应该如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| GET /user_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address.province": "北京"
}
},
{
"match": {
"address.city": "天津"
}
}
]
}
}
}
|
但是得到的结果并不准确,这个时候就需要使用nested object来定义数据建模。
nested object
使用nested object作为地址数组的集体类型,可以解决上述问题,document模型如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| PUT /user_index
{
"mappings": {
"properties": {
"login_name" : {
"type" : "keyword"
},
"age" : {
"type" : "short"
},
"address" : {
"type": "nested",
"properties": {
"province" : {
"type" : "keyword"
},
"city" : {
"type" : "keyword"
},
"street" : {
"type" : "keyword"
}
}
}
}
}
}
|
这个时候就需要使用nested对应的搜索语法来执行搜索了,语法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| GET /user_index/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "address",
"query": {
"bool": {
"must": [
{
"match": {
"address.province": "北京"
}
},
{
"match": {
"address.city": "天津"
}
}
]
}
}
}
}
]
}
}
}
|
虽然语法变的复杂了,但是在数据的读写操作上都不会有错误发生,是推荐的设计方式。
其原因是:
普通的数组数据在ES中会被扁平化处理,处理方式如下:(如果字段需要分词,会将分词数据保存在对应的字段位置,当然应该是一个倒排索引,这里只是一个直观的案例)
1
2
3
4
5
6
| {
"login_name" : "jack",
"address.province" : [ "北京", "天津" ],
"address.city" : [ "北京", "天津" ]
"address.street" : [ "枫林三路", "华夏路" ]
}
|
那么nested object数据类型ES在保存的时候不会有扁平化处理,保存方式如下:所以在搜索的时候一定会有需要的搜索结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
| {
"login_name" : "jack"
}
{
"address.province" : "北京",
"address.city" : "北京",
"address.street" : "枫林三路"
}
{
"address.province" : "天津",
"address.city" : "天津",
"address.street" : "华夏路",
}
|
父子关系数据建模
nested object的建模,有个不好的地方,就是采取的是类似冗余数据的方式,将多个数据都放在一起了,维护成本就比较高
每次更新,需要重新索引整个对象(包括跟对象和嵌套对象)
ES 提供了类似关系型数据库中 Join 的实现。使用 Join 数据类型实现,可以通过 Parent / Child 的关系,从而分离两个对象
父文档和子文档是两个独立的文档
更新父文档无需重新索引整个子文档。子文档被新增,更改和删除也不会影响到父文档和其他子文档。
要点:父子关系元数据映射,用于确保查询时候的高性能,但是有一个限制,就是父子数据必须存在于一个shard中
父子关系数据存在一个shard中,而且还有映射其关联关系的元数据,那么搜索父子关系数据的时候,不用跨分片,一个分片本地自己就搞定了,性能当然高
父子关系
定义父子关系的几个步骤
- 设置索引的 Mapping
- 索引父文档
- 索引子文档
- 按需查询文档
设置 Mapping

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| DELETE my_blogs
# 设定 Parent/Child Mapping
PUT my_blogs
{
"mappings": {
"properties": {
"blog_comments_relation": {
"type": "join",
"relations": {
"blog": "comment"
}
},
"content": {
"type": "text"
},
"title": {
"type": "keyword"
}
}
}
}
|
索引父文档

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| PUT my_blogs/_doc/blog1
{
"title":"Learning Elasticsearch",
"content":"learning ELK is happy",
"blog_comments_relation":{
"name":"blog"
}
}
PUT my_blogs/_doc/blog2
{
"title":"Learning Hadoop",
"content":"learning Hadoop",
"blog_comments_relation":{
"name":"blog"
}
}
|
索引子文档
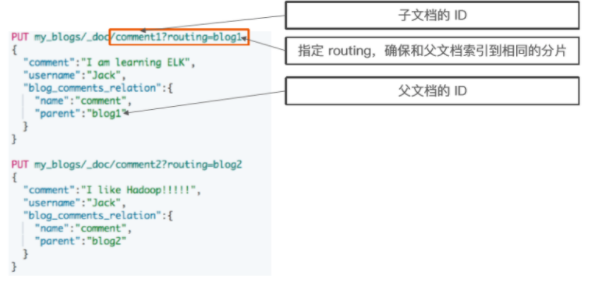
父文档和子文档必须存在相同的分片上
-
当指定文档时候,必须指定它的父文档 ID
-
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| PUT my_blogs/_doc/comment1?routing=blog1
{
"comment":"I am learning ELK",
"username":"Jack",
"blog_comments_relation":{
"name":"comment",
"parent":"blog1"
}
}
PUT my_blogs/_doc/comment2?routing=blog2
{
"comment":"I like Hadoop!!!!!",
"username":"Jack",
"blog_comments_relation":{
"name":"comment",
"parent":"blog2"
}
}
PUT my_blogs/_doc/comment3?routing=blog2
{
"comment":"Hello Hadoop",
"username":"Bob",
"blog_comments_relation":{
"name":"comment",
"parent":"blog2"
}
}
|
Parent / Child 所支持的查询
- 查询所有文档
- Parent Id 查询
- Has Child 查询
- Has Parent 查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| # 查询所有文档
POST my_blogs/_search
{}
#根据父文档ID查看
GET my_blogs/_doc/blog2
# Parent Id 查询
POST my_blogs/_search
{
"query": {
"parent_id": {
"type": "comment",
"id": "blog2"
}
}
}
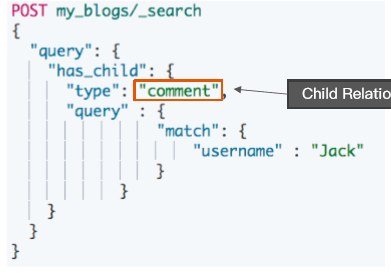
# Has Child 查询,返回父文档
POST my_blogs/_search
{
"query": {
"has_child": {
"type": "comment",
"query" : {
"match": {
"username" : "Jack"
}
}
}
}
}
# Has Parent 查询,返回相关的子文档
POST my_blogs/_search
{
"query": {
"has_parent": {
"parent_type": "blog",
"query" : {
"match": {
"title" : "Learning Hadoop"
}
}
}
}
}
|
使用 has_child 查询
返回父文档
通过对子文档进行查询
- 返回具体相关子文档的父文档
- 父子文档在相同的分片上,因此 Join 效率高
使用 has_parent 查询

使用 parent_id 查询

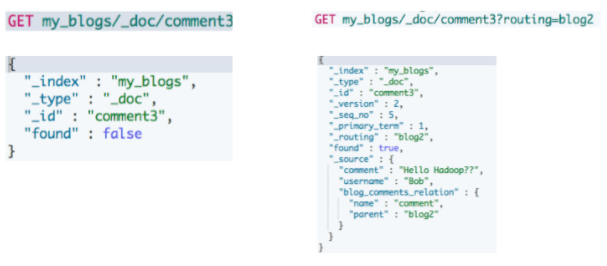
访问子文档
1
2
3
4
5
| #通过ID ,访问子文档
GET my_blogs/_doc/comment2
#通过ID和routing ,访问子文档
GET my_blogs/_doc/comment3?routing=blog2
|
更新子文档
#更新子文档
1
2
3
4
5
6
7
8
| PUT my_blogs/_doc/comment3?routing=blog2
{
"comment": "Hello Hadoop??",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}
|
嵌套对象 v.s 父子文档
Nested Object Parent / Child
优点:文档存储在一起,读取性能高、父子文档可以独立更新
缺点:更新嵌套的子文档时,需要更新整个文档、需要额外的内存去维护关系。读取性能相对差
适用场景子文档偶尔更新,以查询为主、子文档更新频繁
文件系统数据建模
思考一下,github中可以使用代码片段来实现数据搜索。这是如何实现的?
在github中也使用了ES来实现数据的全文搜索。其ES中有一个记录代码内容的索引,大致数据内容如下:
1
2
3
4
5
6
7
8
| {
"fileName" : "HelloWorld.java",
"authName" : "baiqi",
"authID" : 110,
"productName" : "first-java",
"path" : "/com/baiqi/first",
"content" : "package com.baiqi.first; public class HelloWorld { //code... }"
}
|
我们可以在github中通过代码的片段来实现数据的搜索。也可以使用其他条件实现数据搜索。但是,如果需要使用文件路径搜索内容应该如何实现?这个时候需要为其中的字段path定义一个特殊的分词器。具体如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
| PUT /codes
{
"settings": {
"analysis": {
"analyzer": {
"path_analyzer" : {
"tokenizer" : "path_hierarchy"
}
}
}
},
"mappings": {
"properties": {
"fileName" : {
"type" : "keyword"
},
"authName" : {
"type" : "text",
"analyzer": "standard",
"fields": {
"keyword" : {
"type" : "keyword"
}
}
},
"authID" : {
"type" : "long"
},
"productName" : {
"type" : "text",
"analyzer": "standard",
"fields": {
"keyword" : {
"type" : "keyword"
}
}
},
"path" : {
"type" : "text",
"analyzer": "path_analyzer",
"fields": {
"keyword" : {
"type" : "keyword"
}
}
},
"content" : {
"type" : "text",
"analyzer": "standard"
}
}
}
}
PUT /codes/_doc/1
{
"fileName" : "HelloWorld.java",
"authName" : "baiqi",
"authID" : 110,
"productName" : "first-java",
"path" : "/com/baiqi/first",
"content" : "package com.baiqi.first; public class HelloWorld { // some code... }"
}
GET /codes/_search
{
"query": {
"match": {
"path": "/com"
}
}
}
GET /codes/_analyze
{
"text": "/a/b/c/d",
"field": "path"
}
############################################################################################################
PUT /codes
{
"settings": {
"analysis": {
"analyzer": {
"path_analyzer" : {
"tokenizer" : "path_hierarchy"
}
}
}
},
"mappings": {
"properties": {
"fileName" : {
"type" : "keyword"
},
"authName" : {
"type" : "text",
"analyzer": "standard",
"fields": {
"keyword" : {
"type" : "keyword"
}
}
},
"authID" : {
"type" : "long"
},
"productName" : {
"type" : "text",
"analyzer": "standard",
"fields": {
"keyword" : {
"type" : "keyword"
}
}
},
"path" : {
"type" : "text",
"analyzer": "path_analyzer",
"fields": {
"keyword" : {
"type" : "text",
"analyzer": "standard"
}
}
},
"content" : {
"type" : "text",
"analyzer": "standard"
}
}
}
}
GET /codes/_search
{
"query": {
"match": {
"path.keyword": "/com"
}
}
}
GET /codes/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"path": "/com"
}
},
{
"match": {
"path.keyword": "/com/baiqi"
}
}
]
}
}
}
|
参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-pathhierarchy-tokenizer.html
参考链接