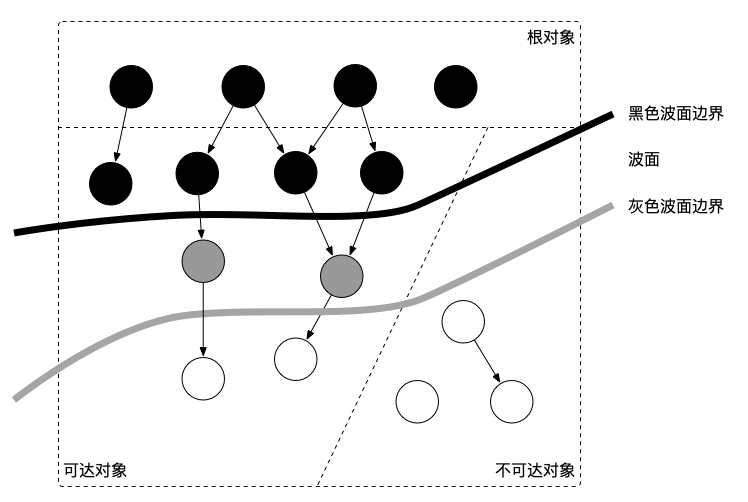
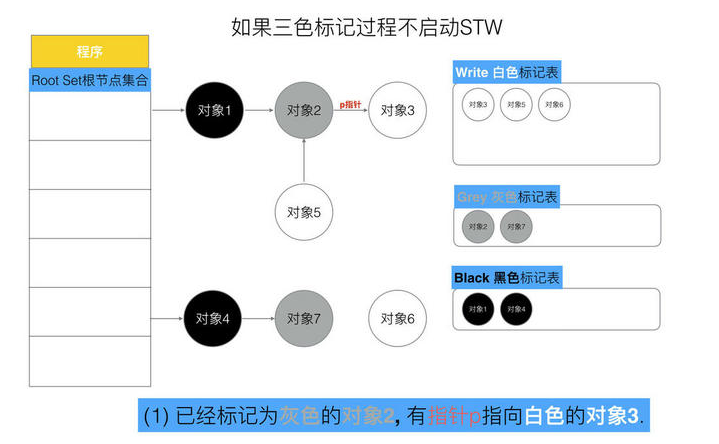
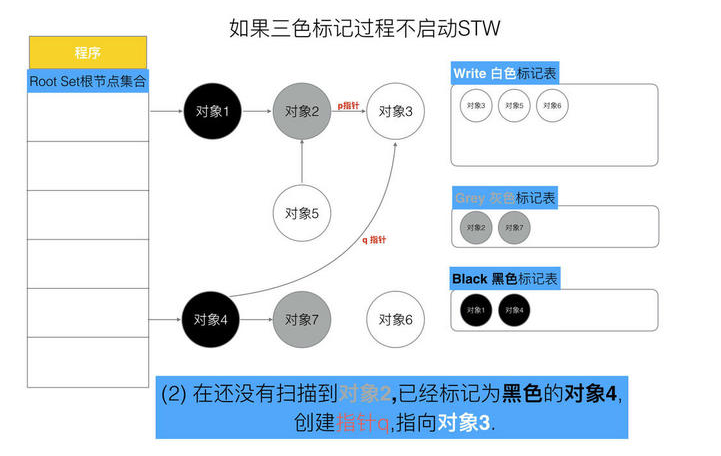
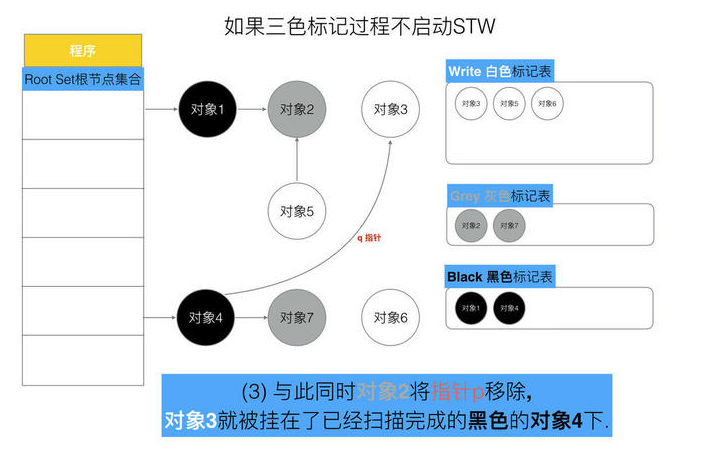
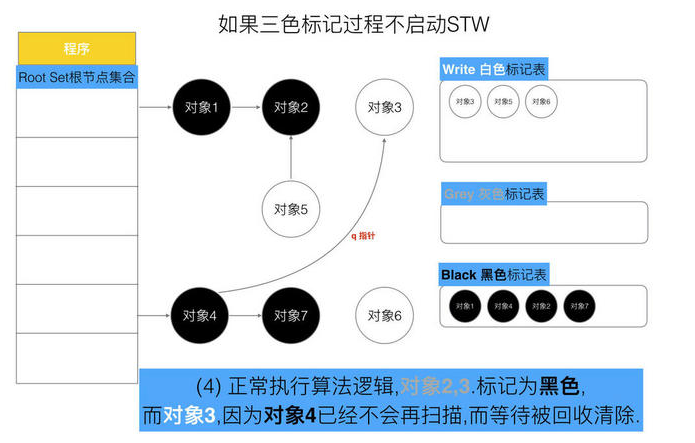
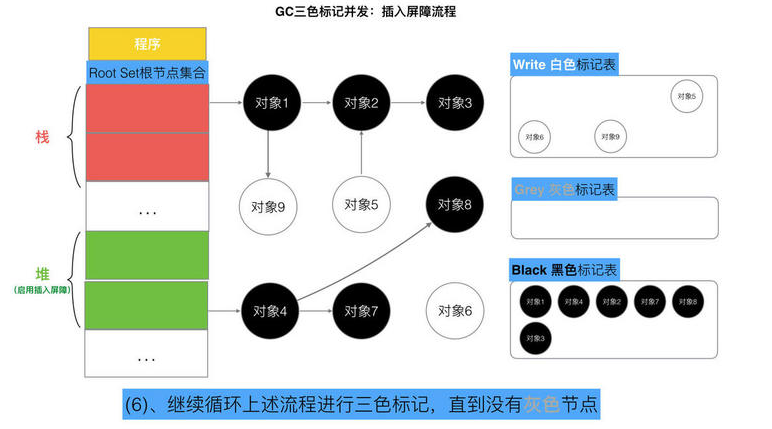
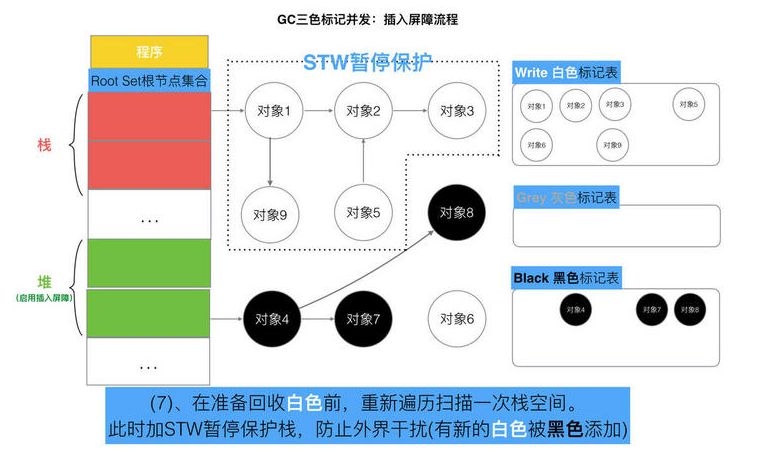
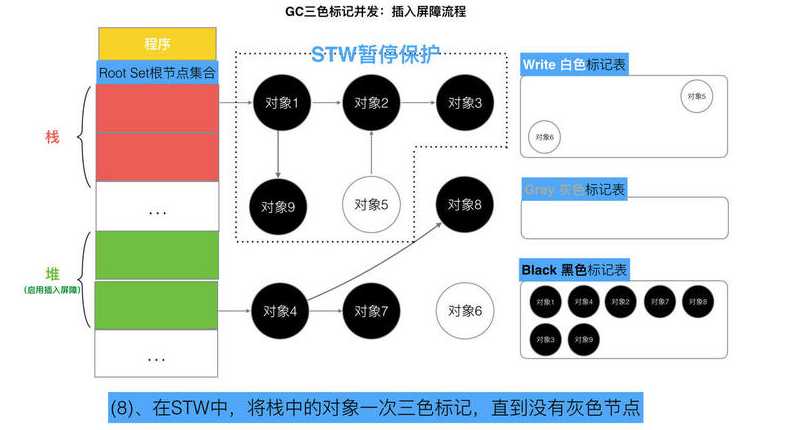
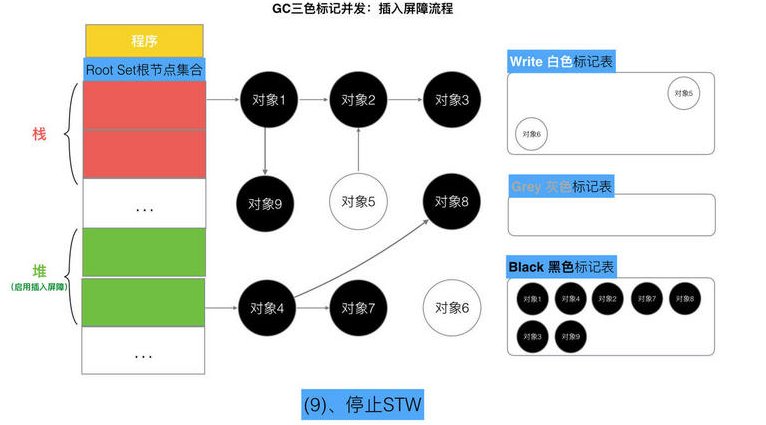
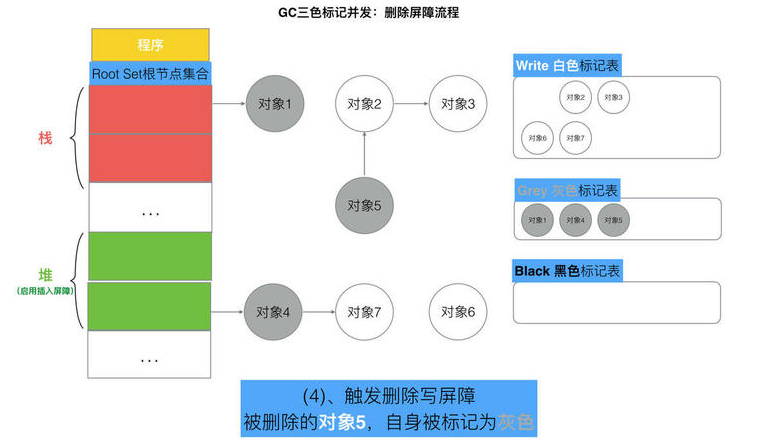
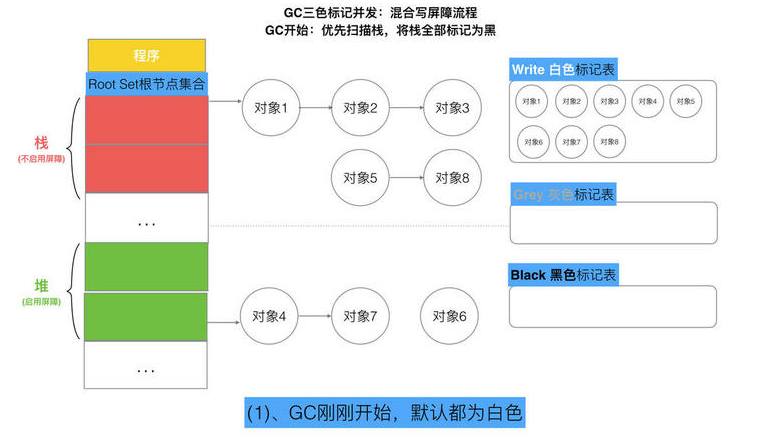
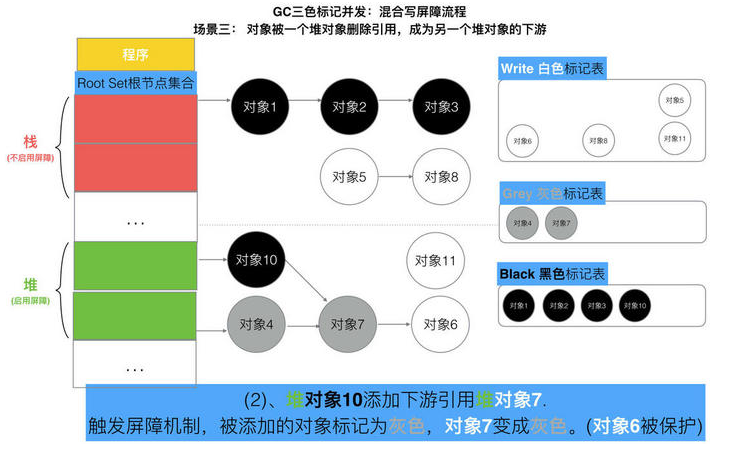
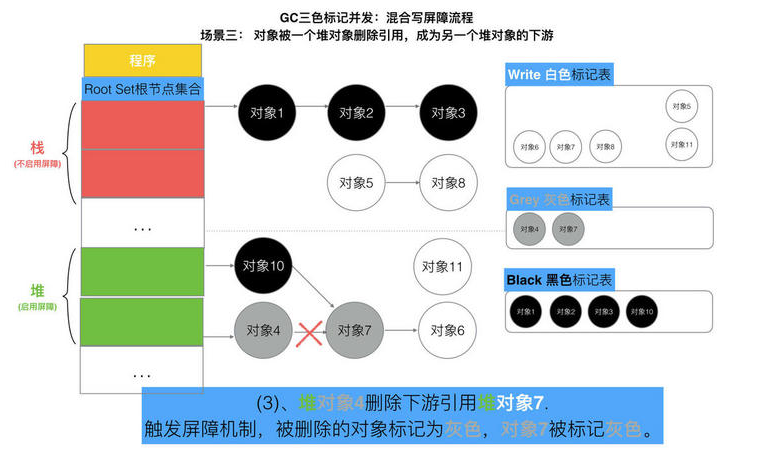
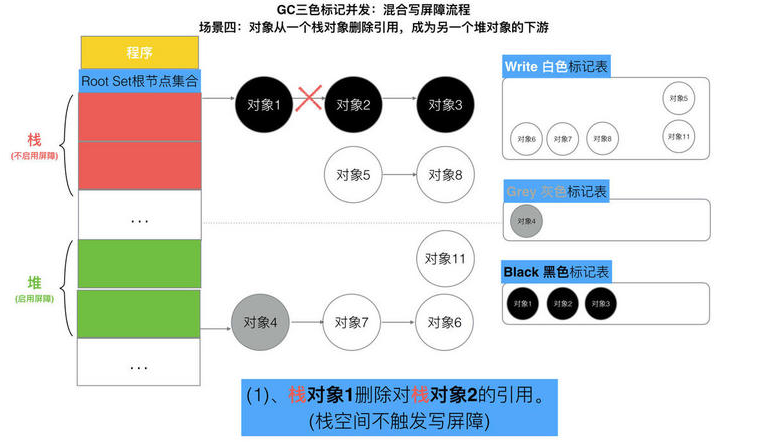
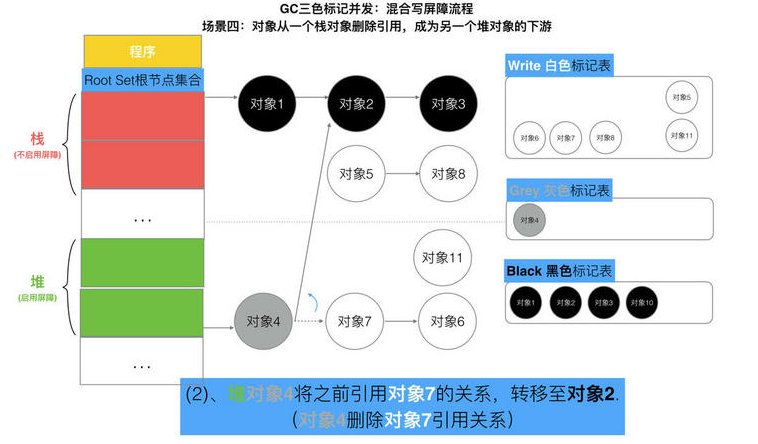
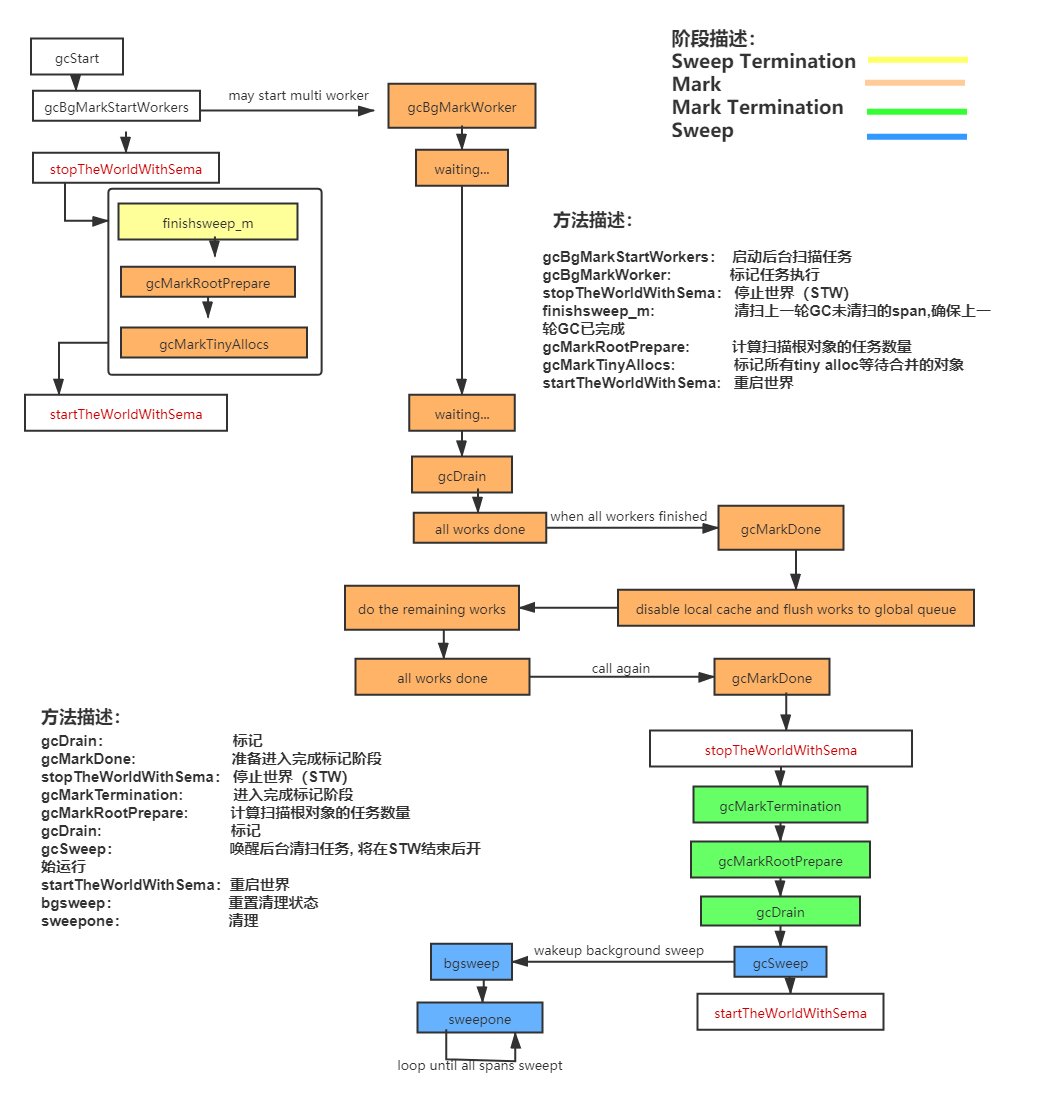
// 记录开始时间 now := nanotime() work.tSweepTerm = now work.pauseStart = now // 停止所有运行中的G, 并禁止它们运行 systemstack(stopTheWorldWithSema) // !!!!!!!!!!!!!!!! // 世界已停止(STW)... // !!!!!!!!!!!!!!!! // 清扫上一轮GC未清扫的span, 确保上一轮GC已完成 // Finish sweep before we start concurrent scan. systemstack(func() { finishsweep_m() }) // 清扫sched.sudogcache和sched.deferpool clearpools()
// 增加GC计数 work.cycles++ // 判断是否并行GC模式 if mode == gcBackgroundMode { // Do as much work concurrently as possible // 标记新一轮GC已开始 gcController.startCycle() work.heapGoal = memstats.next_gc
lock(&sched.lock) // 需要停止的P数量 sched.stopwait = gomaxprocs // 设置gc等待标记, 调度时看见此标记会进入等待 atomic.Store(&sched.gcwaiting, 1) // 抢占所有运行中的G preemptall() // 停止当前的P // stop current P _g_.m.p.ptr().status = _Pgcstop // Pgcstop is only diagnostic. // 减少需要停止的P数量(当前的P算一个) sched.stopwait-- // 抢占所有在Psyscall状态的P, 防止它们重新参与调度 // try to retake all P's in Psyscall status for i := 0; i < int(gomaxprocs); i++ { p := allp[i] s := p.status if s == _Psyscall && atomic.Cas(&p.status, s, _Pgcstop) { if trace.enabled { traceGoSysBlock(p) traceProcStop(p) } p.syscalltick++ sched.stopwait-- } } // 防止所有空闲的P重新参与调度 // stop idle P's for { p := pidleget() if p == nil { break } p.status = _Pgcstop sched.stopwait-- } wait := sched.stopwait > 0 unlock(&sched.lock)
// 如果仍有需要停止的P, 则等待它们停止 // wait for remaining P's to stop voluntarily if wait { for { // 循环等待 + 抢占所有运行中的G // wait for 100us, then try to re-preempt in case of any races ifnotetsleep(&sched.stopnote, 100*1000){ noteclear(&sched.stopnote) break } preemptall() } }
// 逻辑正确性检查 // sanity checks bad := "" if sched.stopwait != 0 { bad = "stopTheWorld: not stopped (stopwait != 0)" } else { for i := 0; i < int(gomaxprocs); i++ { p := allp[i] if p.status != _Pgcstop { bad = "stopTheWorld: not stopped (status != _Pgcstop)" } } } if atomic.Load(&freezing) != 0 { lock(&deadlock) lock(&deadlock) } if bad != "" { throw(bad) } // 到这里所有运行中的G都会变为待运行, 并且所有的P都不能被M获取 // 也就是说所有的go代码(除了当前的)都会停止运行, 并且不能运行新的go代码 }
// 计算block数量的函数, rootBlockBytes是256KB // Compute how many data and BSS root blocks there are. nBlocks := func(bytes uintptr) int { returnint((bytes + rootBlockBytes - 1) / rootBlockBytes) }
work.nDataRoots = 0 work.nBSSRoots = 0
// data和bss每一轮GC只扫描一次 // 并行GC中会在后台标记任务中扫描, 完成标记阶段(mark termination)中不扫描 // 非并行GC会在完成标记阶段(mark termination)中扫描 // Only scan globals once per cycle; preferably concurrently. if !work.markrootDone { // 计算扫描可读写的全局变量的任务数量 for _, datap := range activeModules(){ nDataRoots := nBlocks(datap.edata - datap.data) if nDataRoots > work.nDataRoots { work.nDataRoots = nDataRoots } }
// 计算扫描只读的全局变量的任务数量 for _, datap := range activeModules(){ nBSSRoots := nBlocks(datap.ebss - datap.bss) if nBSSRoots > work.nBSSRoots { work.nBSSRoots = nBSSRoots } } }
switch { // 释放mcache中的所有span, 要求STW case baseFlushCache <= i && i < baseData: flushmcache(int(i - baseFlushCache))
// 扫描可读写的全局变量 // 这里只会扫描i对应的block, 扫描时传入包含哪里有指针的bitmap数据 case baseData <= i && i < baseBSS: for _, datap := range activeModules(){ markrootBlock(datap.data, datap.edata-datap.data, datap.gcdatamask.bytedata, gcw, int(i-baseData)) }
// 扫描只读的全局变量 // 这里只会扫描i对应的block, 扫描时传入包含哪里有指针的bitmap数据 case baseBSS <= i && i < baseSpans: for _, datap := range activeModules(){ markrootBlock(datap.bss, datap.ebss-datap.bss, datap.gcbssmask.bytedata, gcw, int(i-baseBSS)) }
// 扫描析构器队列 case i == fixedRootFinalizers: if work.markrootDone { break } for fb := allfin; fb != nil; fb = fb.alllink { cnt := uintptr(atomic.Load(&fb.cnt)) scanblock(uintptr(unsafe.Pointer(&fb.fin[0])), cnt*unsafe.Sizeof(fb.fin[0]), &finptrmask[0], gcw) }
// 释放已中止的G的栈 case i == fixedRootFreeGStacks: if !work.markrootDone { systemstack(markrootFreeGStacks) }
// 扫描各个span中特殊对象(析构器列表) case baseSpans <= i && i < baseStacks: // mark MSpan.specials markrootSpans(gcw, int(i-baseSpans))
// 扫描各个G的栈 default: // 获取需要扫描的G var gp *g if baseStacks <= i && i < end { gp = allgs[i-baseStacks] } else { throw("markroot: bad index") }
// 记录等待开始的时间 if (status == _Gwaiting || status == _Gsyscall) && gp.waitsince == 0 { gp.waitsince = work.tstart }
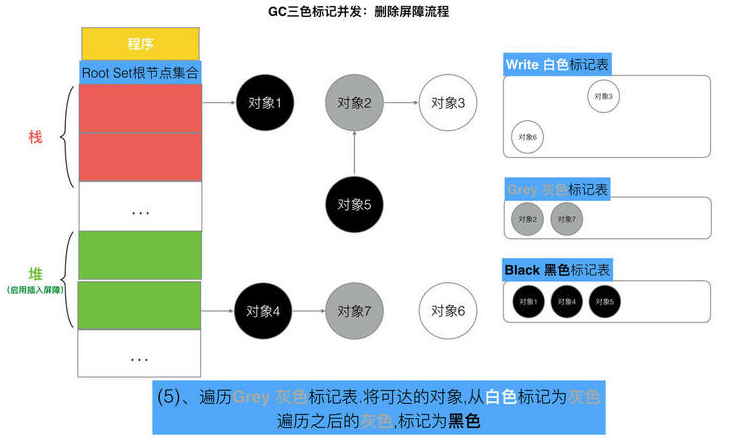
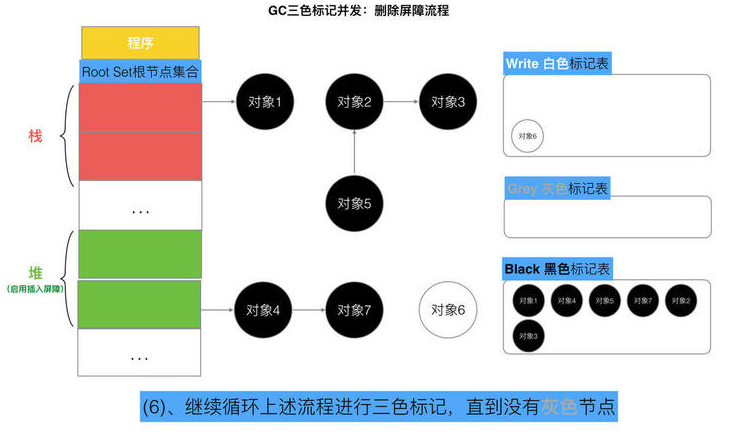
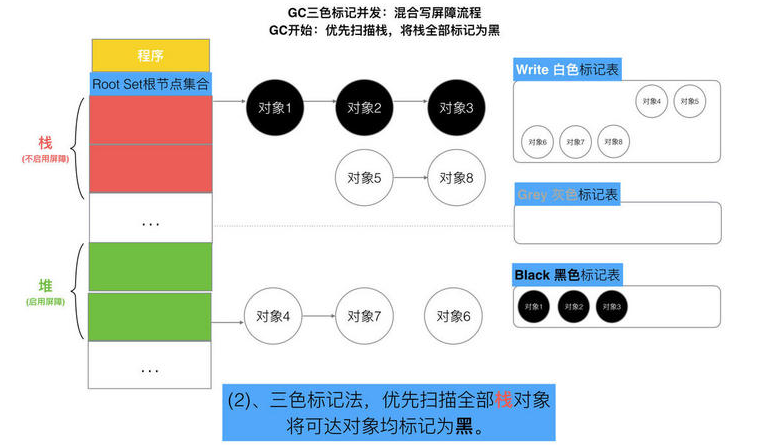
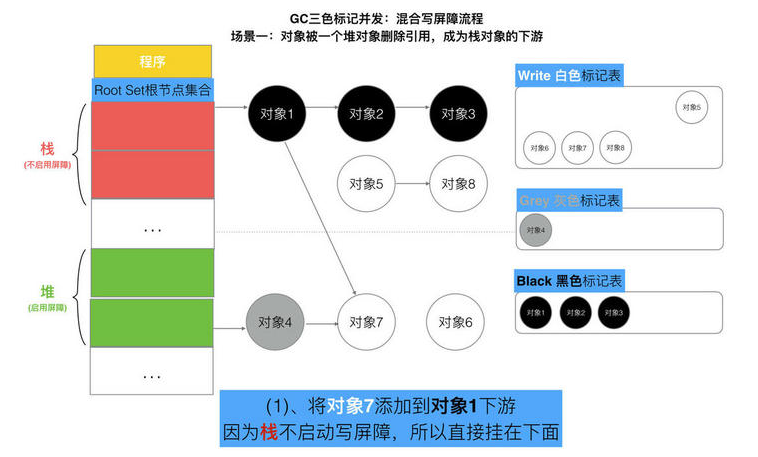
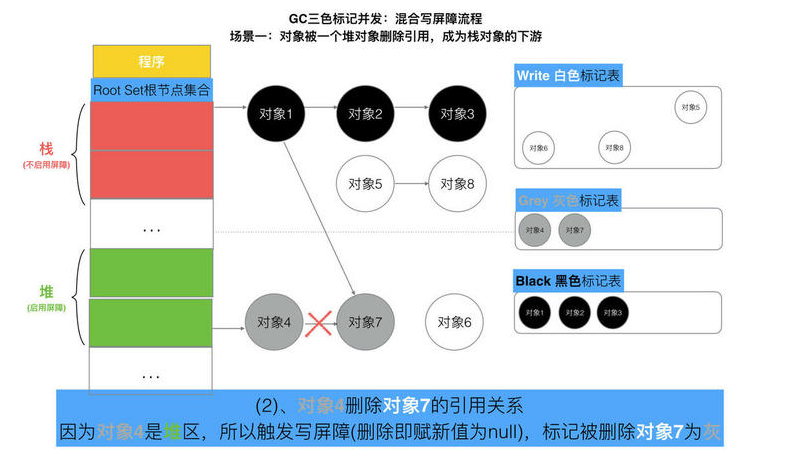
// Still in STW but gcphase is _GCoff, reset to _GCmarktermination // At this point all objects will be found during the gcMark which // does a complete STW mark and object scan. setGCPhase(_GCmarktermination) gcMark(startTime) setGCPhase(_GCoff) // marking is done, turn off wb. gcSweep(work.mode) } })
// 更新用时记录 // Update timing memstats now := nanotime() sec, nsec, _ := time_now() unixNow := sec*1e9 + int64(nsec) work.pauseNS += now - work.pauseStart work.tEnd = now atomic.Store64(&memstats.last_gc_unix, uint64(unixNow)) // must be Unix time to make sense to user atomic.Store64(&memstats.last_gc_nanotime, uint64(now)) // monotonic time for us memstats.pause_ns[memstats.numgc%uint32(len(memstats.pause_ns))] = uint64(work.pauseNS) memstats.pause_end[memstats.numgc%uint32(len(memstats.pause_end))] = uint64(unixNow) memstats.pause_total_ns += uint64(work.pauseNS)
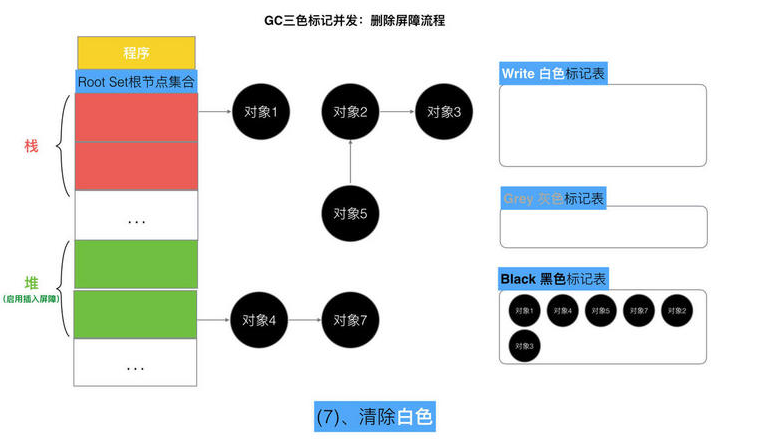
func gcSweep(mode gcMode){ if gcphase != _GCoff { throw("gcSweep being done but phase is not GCoff") }
// 增加sweepgen, 这样sweepSpans中两个队列角色会交换, 所有span都会变为"待清扫"的span lock(&mheap_.lock) mheap_.sweepgen += 2 mheap_.sweepdone = 0 if mheap_.sweepSpans[mheap_.sweepgen/2%2].index != 0 { // We should have drained this list during the last // sweep phase. We certainly need to start this phase // with an empty swept list. throw("non-empty swept list") } mheap_.pagesSwept = 0 unlock(&mheap_.lock)
// 如果非并行GC则在这里完成所有工作(STW中) if !_ConcurrentSweep || mode == gcForceBlockMode { // Special case synchronous sweep. // Record that no proportional sweeping has to happen. lock(&mheap_.lock) mheap_.sweepPagesPerByte = 0 unlock(&mheap_.lock) // Sweep all spans eagerly. forsweepone() != ^uintptr(0) { sweep.npausesweep++ } // Free workbufs eagerly. prepareFreeWorkbufs() forfreeSomeWbufs(false){ } mProf_NextCycle() mProf_Flush() return }
// 禁止G被抢占 // increment locks to ensure that the goroutine is not preempted // in the middle of sweep thus leaving the span in an inconsistent state for next GC _g_.m.locks++ // 检查是否已完成清扫 if atomic.Load(&mheap_.sweepdone) != 0 { _g_.m.locks-- return ^uintptr(0) } // 更新同时执行sweep的任务数量 atomic.Xadd(&mheap_.sweepers, +1)
npages := ^uintptr(0) sg := mheap_.sweepgen for { // 从sweepSpans中取出一个span s := mheap_.sweepSpans[1-sg/2%2].pop() // 全部清扫完毕时跳出循环 if s == nil { atomic.Store(&mheap_.sweepdone, 1) break } // 其他M已经在清扫这个span时跳过 if s.state != mSpanInUse { // This can happen if direct sweeping already // swept this span, but in that case the sweep // generation should always be up-to-date. if s.sweepgen != sg { print("runtime: bad span s.state=", s.state, " s.sweepgen=", s.sweepgen, " sweepgen=", sg, "\n") throw("non in-use span in unswept list") } continue } // 原子增加span的sweepgen, 失败表示其他M已经开始清扫这个span, 跳过 if s.sweepgen != sg-2 || !atomic.Cas(&s.sweepgen, sg-2, sg-1) { continue } // 清扫这个span, 然后跳出循环 npages = s.npages if !s.sweep(false) { // Span is still in-use, so this returned no // pages to the heap and the span needs to // move to the swept in-use list. npages = 0 } break }
// 更新同时执行sweep的任务数量 // Decrement the number of active sweepers and if this is the // last one print trace information. if atomic.Xadd(&mheap_.sweepers, -1) == 0 && atomic.Load(&mheap_.sweepdone) != 0 { if debug.gcpacertrace > 0 { print("pacer: sweep done at heap size ", memstats.heap_live>>20, "MB; allocated ", (memstats.heap_live-mheap_.sweepHeapLiveBasis)>>20, "MB during sweep; swept ", mheap_.pagesSwept, " pages at ", sweepRatio, " pages/byte\n") } } // 允许G被抢占 _g_.m.locks-- // 返回清扫的页数 return npages }
func (s *mspan) sweep(preserve bool) bool { // It's critical that we enter this function with preemption disabled, // GC must not start while we are in the middle of this function. _g_ := getg() if _g_.m.locks == 0 && _g_.m.mallocing == 0 && _g_ != _g_.m.g0 { throw("MSpan_Sweep: m is not locked") } sweepgen := mheap_.sweepgen if s.state != mSpanInUse || s.sweepgen != sweepgen-1 { print("MSpan_Sweep: state=", s.state, " sweepgen=", s.sweepgen, " mheap.sweepgen=", sweepgen, "\n") throw("MSpan_Sweep: bad span state") }
if trace.enabled { traceGCSweepSpan(s.npages * _PageSize) }
spc := s.spanclass size := s.elemsize res := false
c := _g_.m.mcache freeToHeap := false
// 判断在special中的析构器, 如果对应的对象已经不再存活则标记对象存活防止回收, 然后把析构器移到运行队列 specialp := &s.specials special := *specialp for special != nil { // A finalizer can be set for an inner byte of an object, find object beginning. objIndex := uintptr(special.offset) / size p := s.base() + objIndex*size mbits := s.markBitsForIndex(objIndex) if !mbits.isMarked() { // This object is not marked and has at least one special record. // Pass 1: see if it has at least one finalizer. hasFin := false endOffset := p - s.base() + size for tmp := special; tmp != nil && uintptr(tmp.offset) < endOffset; tmp = tmp.next { if tmp.kind == _KindSpecialFinalizer { // Stop freeing of object if it has a finalizer. mbits.setMarkedNonAtomic() hasFin = true break } } // Pass 2: queue all finalizers _or_ handle profile record. for special != nil && uintptr(special.offset) < endOffset { // Find the exact byte for which the special was setup // (as opposed to object beginning). p := s.base() + uintptr(special.offset) if special.kind == _KindSpecialFinalizer || !hasFin { // Splice out special record. y := special special = special.next *specialp = special freespecial(y, unsafe.Pointer(p), size) } else { // This is profile record, but the object has finalizers (so kept alive). // Keep special record. specialp = &special.next special = *specialp } } } else { // object is still live: keep special record specialp = &special.next special = *specialp } }
// 除错用 if debug.allocfreetrace != 0 || raceenabled || msanenabled { // Find all newly freed objects. This doesn't have to // efficient; allocfreetrace has massive overhead. mbits := s.markBitsForBase() abits := s.allocBitsForIndex(0) for i := uintptr(0); i < s.nelems; i++ { if !mbits.isMarked() && (abits.index < s.freeindex || abits.isMarked()) { x := s.base() + i*s.elemsize if debug.allocfreetrace != 0 { tracefree(unsafe.Pointer(x), size) } if raceenabled { racefree(unsafe.Pointer(x), size) } if msanenabled { msanfree(unsafe.Pointer(x), size) } } mbits.advance() abits.advance() } }
// 计算释放的对象数量 // Count the number of free objects in this span. nalloc := uint16(s.countAlloc()) if spc.sizeclass() == 0 && nalloc == 0 { // 如果span的类型是0(大对象)并且其中的对象已经不存活则释放到heap s.needzero = 1 freeToHeap = true } nfreed := s.allocCount - nalloc if nalloc > s.allocCount { print("runtime: nelems=", s.nelems, " nalloc=", nalloc, " previous allocCount=", s.allocCount, " nfreed=", nfreed, "\n") throw("sweep increased allocation count") }
// 重置freeindex, 下次分配从0开始搜索 s.freeindex = 0// reset allocation index to start of span. if trace.enabled { getg().m.p.ptr().traceReclaimed += uintptr(nfreed) * s.elemsize }
// gcmarkBits变为新的allocBits // 然后重新分配一块全部为0的gcmarkBits // 下次分配对象时可以根据allocBits得知哪些元素是未分配的 // gcmarkBits becomes the allocBits. // get a fresh cleared gcmarkBits in preparation for next GC s.allocBits = s.gcmarkBits s.gcmarkBits = newMarkBits(s.nelems)
// 如果span中已经无存活的对象则更新sweepgen到最新 // 下面会把span加到mcentral或者mheap // We need to set s.sweepgen = h.sweepgen only when all blocks are swept, // because of the potential for a concurrent free/SetFinalizer. // But we need to set it before we make the span available for allocation // (return it to heap or mcentral), because allocation code assumes that a // span is already swept if available for allocation. if freeToHeap || nfreed == 0 { // The span must be in our exclusive ownership until we update sweepgen, // check for potential races. if s.state != mSpanInUse || s.sweepgen != sweepgen-1 { print("MSpan_Sweep: state=", s.state, " sweepgen=", s.sweepgen, " mheap.sweepgen=", sweepgen, "\n") throw("MSpan_Sweep: bad span state after sweep") } atomic.Store(&s.sweepgen, sweepgen) }
if nfreed > 0 && spc.sizeclass() != 0 { // 把span加到mcentral, res等于是否添加成功 c.local_nsmallfree[spc.sizeclass()] += uintptr(nfreed) res = mheap_.central[spc].mcentral.freeSpan(s, preserve, wasempty) // freeSpan会更新sweepgen // MCentral_FreeSpan updates sweepgen } elseif freeToHeap { // 把span释放到mheap // Free large span to heap if debug.efence > 0 { s.limit = 0// prevent mlookup from finding this span sysFault(unsafe.Pointer(s.base()), size) } else { mheap_.freeSpan(s, 1) } c.local_nlargefree++ c.local_largefree += size res = true } // 如果span未加到mcentral或者未释放到mheap, 则表示span仍在使用 if !res { // 把仍在使用的span加到sweepSpans的"已清扫"队列中 // The span has been swept and is still in-use, so put // it on the swept in-use list. mheap_.sweepSpans[sweepgen/2%2].push(s) } return res }